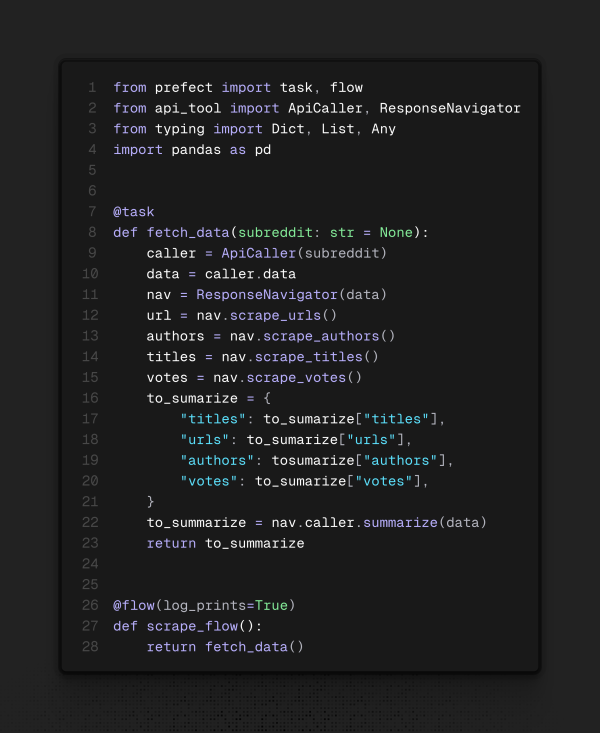
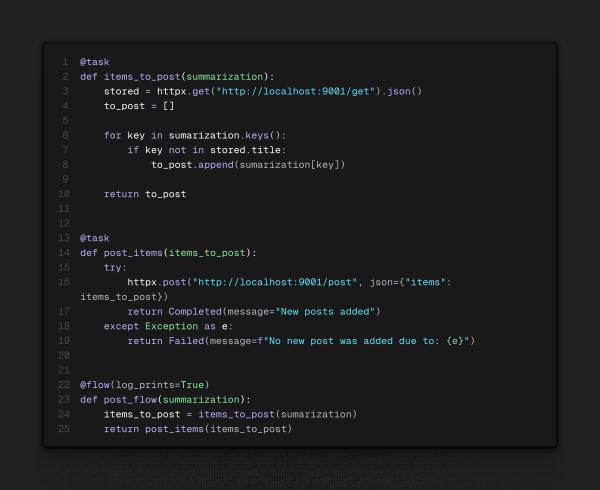
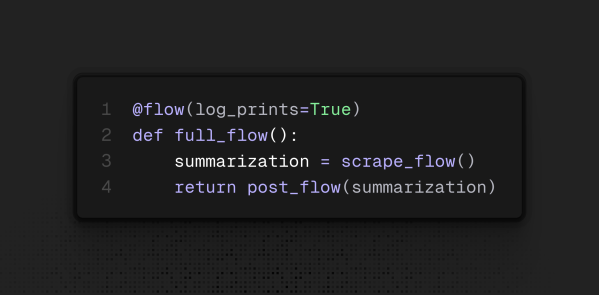
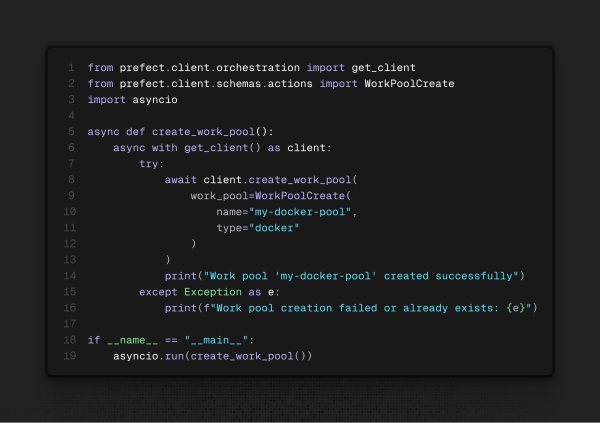
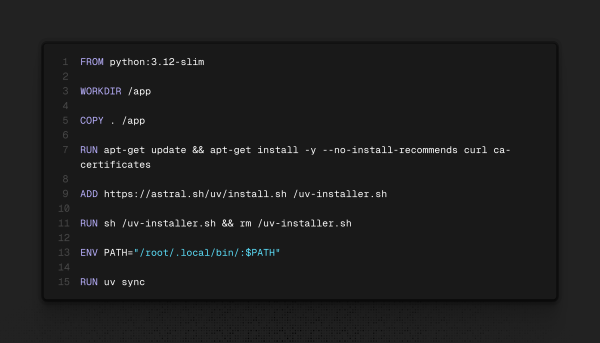
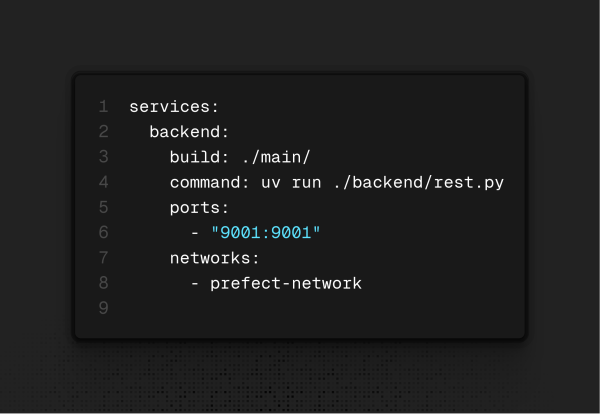
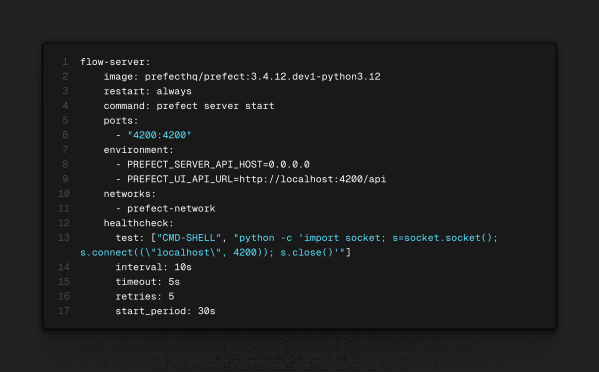
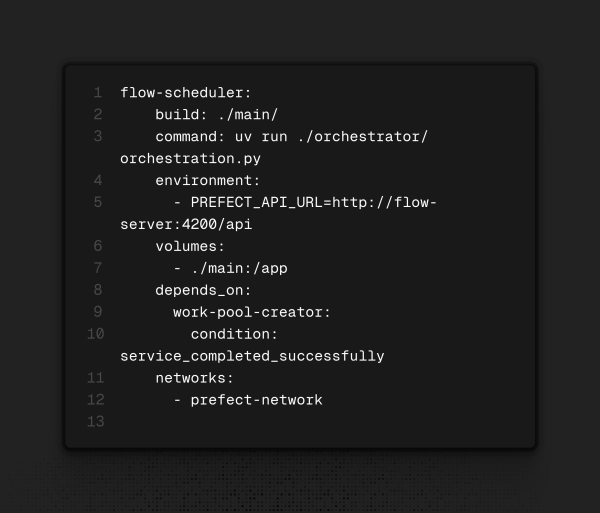
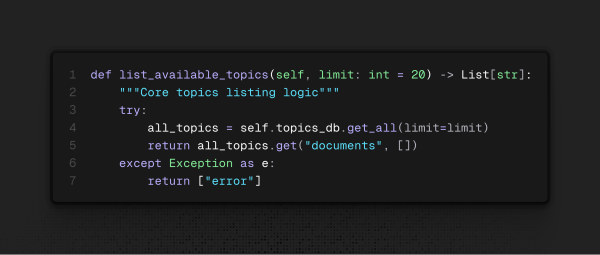
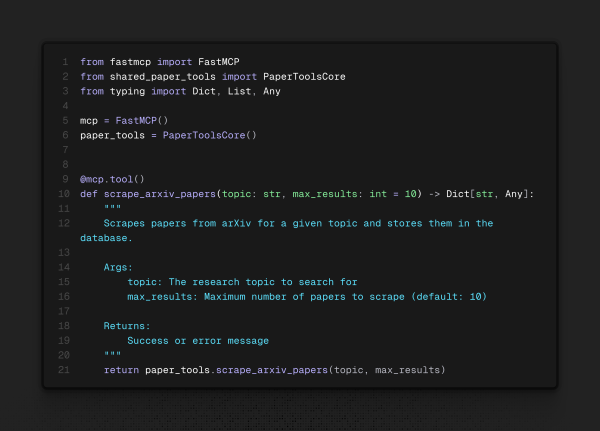
Dando um passo atrás
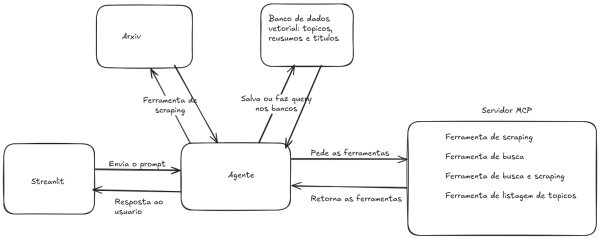
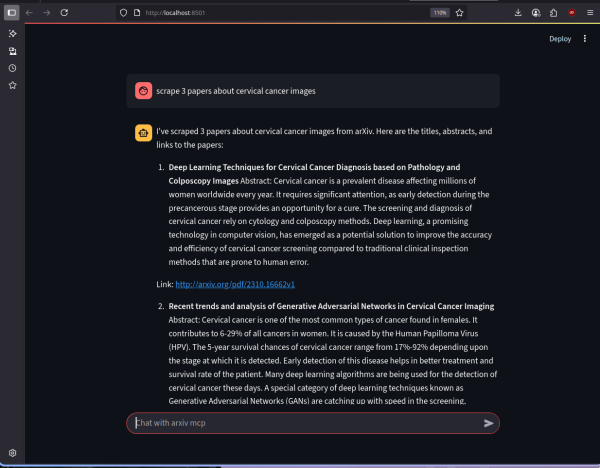
No meu post de meu agente MCP arxiv, acabei pulando degraus do conhecimento para AI engineers mais novos. Aqui definirei pontos importantes para entender melhor o que são agentes. Estou levando em consideração que no momento sabem conceitos de LLMs, englobando os conceitos que levam à arquitetura transformer. Terão posts mais à frente explicando em detalhes a base matemática desses modelos. Nesse post tenho a intenção de introduzir o que é um agente e o que o constitui, o que faz um bom agente e engenharia de software básica para uma boa criação de agentes.
O que é um agente?
Um agente é um acoplado entre uma LLM e chamada de funções que chamamos de ferramentas. A LLM (ou SLM, a depender) interpreta o que é passado e chama a ferramenta adequada se necessário. Imagine que temos uma LLM qualquer com instruções de ser um professor de matemática e tem ferramentas como → soma, subtração, divisão e produto. Se o aluno pedir algo que o agente ache necessário chamar as ferramentas provisionadas, ele usará com os parâmetros interpretados. Esse background será explicado passo a passo a seguir.
Esqueleto de uma LLM
Uma LLM tem como base o mecanismo de atenção. Esse mecanismo vem do conceito de autoregressão de NLP. Imagine que você quer prever a próxima “palavra” digitada por uma pessoa e ela começa a digitar a seguinte frase:
Hoje foi um dia ...
Veja, para você é muito mais intuitivo a próxima “palavra” ser algo como “cansativo” ou “produtivo” e não uma palavra como “verde”. Isso se deve ao que o mecanismo de atenção emula. Cada “palavra” gera uma probabilidade à qual treinamos o modelo a gerar a próxima “palavra”. Em resumo, atenção olha para o contexto e adapta para gerar o que lhe foi treinado. Coloquei “palavra” de propósito já que modelos de deep learning treinam a partir de números e então precisamos converter palavras ou tokens da nossa língua para o modelo, podendo partir de codificar letras, palavras ou frases numericamente. Tokens são os átomos da nossa estrutura do modelo de linguagem.
Tokens: os átomos de uma LLM
Ilustrei tokens como sendo o átomo da nossa LLM, ou seja, a menor partícula de linguagem codificada para o nosso modelo. Intuitivamente, podemos ligar a palavras ou letras e, de fato, quando criado foi utilizada de tal forma com o modelo de tokenização word2vec (palavra para vetor). Mas saber qual tokenização utilizar é de extrema importância para que nosso modelo saiba generalizar bem. De certa forma, mais palavras no nosso conjunto de tokens ou dialeto mais distribuímos a probabilidade no dialeto. Contudo, como o prompt inicial e a tarefa influenciam diretamente o resultado, podemos modelar para cada problema. Alguns exemplos de encoding: BPE (byte pair encoding) ou SentencePiece, que estão em alta.
Encoders, Decoders, Encoder-Decoders
Encoders
Certo, agora que foi introduzida a base de LLMs e como recebem os dados, devo aprofundar mais. Os modelos focados em transformar as palavras em números serão muito úteis. Serão considerados vetores para podermos segregar significados de cada palavra. São os encoders. De acordo com como treinamos, podemos agrupar palavras como desejarmos. Mas dando um passo atrás, se gerássemos apenas um número por palavra teríamos um problema por imaginarmos uma reta. Como criaríamos um sentido para isso? Existem diversas maneiras de ordenar. Digamos, em uma dimensão com 2 dimensões, podemos decidir agrupar por quão próximas são palavras relacionadas, animais ou não animais, por exemplo, deixando algo nesse estilo:
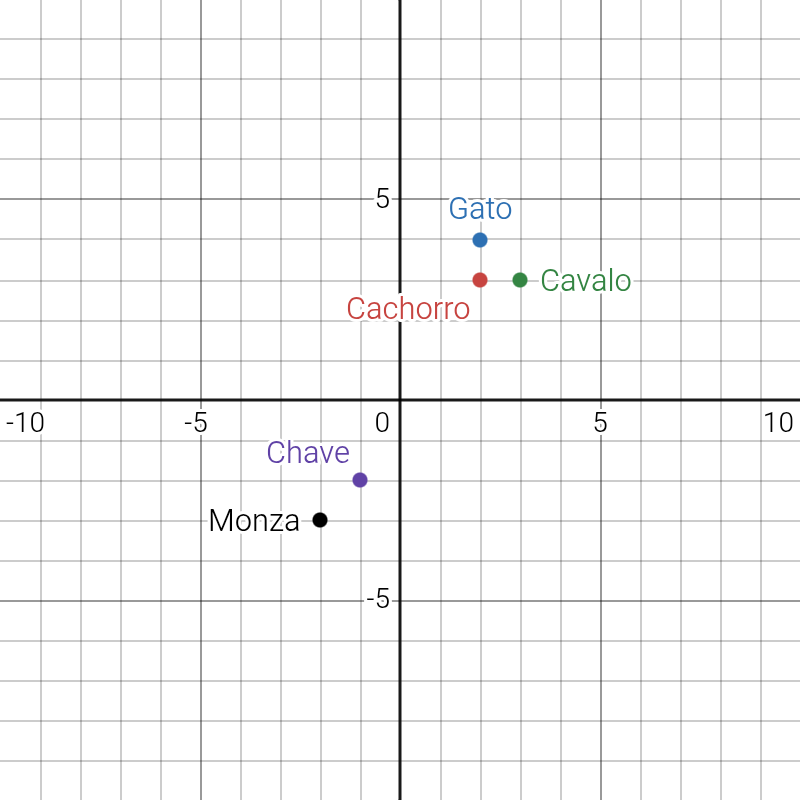
Mas conforme queremos ordenar por alguma ideia, aumentamos o grau de dimensionalidade. Atualmente, o GemmaEncoder, por exemplo, utiliza vetores de 768 dimensões. Alguns modelos: BERT, RoBERTa, ALBERT… Esses modelos são utilizados para NLU (Natural Language Understanding) ou compreensão de linguagem natural, além de que são as peças fundamentais para bancos de dados vetoriais para os famosos RAGs.
Decoders
Decoders, como deve ter imaginado, decodificam o vetor. Mas os modelos fazem além disso: eles são os que preveem a próxima palavra que foi repassada. Modelos conhecidos são o ChatGPT-3, 4 e LLaMA. Modelos com intuito de geração de texto e conversação usam essa arquitetura. Agora, com isso, explica-se o que é tanto dito sobre o ChatGPT querer agradar o usuário — ele foi treinado para isso. A depender de cada token que o usuário enviou, ele pode tomar uma postura diferente. Dito isso, podemos treinar um decoder para completar como quisermos, seja com uma postura que seriam palavras que Machado de Assis escreveria ou sendo extremamente desagradável ao usuário. Cabe a quem está criando escolher.
Encoder-Decoder
Esse modelo junta as arquiteturas citadas para associar um vetor de um mapeamento a outro, sendo essencial para tradução de uma língua a outra, resumir textos, responder perguntas e geração de código (que não deixa de ser uma tradução). Exemplo de modelos seriam o T5 e BART para traduções e PEGASUS para resumir textos.
O que isso tem a ver com agentes?
Agentes são, de maneira bem simplificada, uma LLM que interpreta o que o usuário pediu e decide qual será o próximo passo. Voltando ao exemplo do agente professor, digamos que um aluno está com dúvida de qual resultado vem de 3 * 5. Se o agente for bem treinado, ele irá interpretar que esse pedido requer a ferramenta de multiplicação, então ele irá chamar a ferramenta multiplicação com parâmetros interpretados “3” e “5” e retorna ao usuário o resultado pedido.
Agora imagine que temos um caso mais complexo, um agente de emergência médica. Um paciente descreve os sintomas e, a depender da interpretação do agente, ele pode usar uma das ferramentas: chamar ambulância caso o caso seja urgente, indicar a triagem humana ou colocar na fila de espera de uma especializada. Se um paciente começa a conversar normalmente e dá sinais de um AVC, por exemplo, ele pode invocar a ferramenta de ambulância, ou, se for algo indeterminado para ele, pode passar para triagem humana. Claro que simplifiquei muito. Pode haver associação de agentes — um agente que coordena qual agente chamar — mas deixo aqui só o que pode ser utilizado.
O que faz um bom agente?
No campo de inteligência artificial, podemos mensurar de diversas formas como um modelo nos é útil, e para agentes não é diferente. Temos alguns exemplos: CSAT (Customer Satisfaction Score), Script Adherence Rate, Internal Quality Score (IQS), etc… Existem mais de 25 métricas. Cabe ao desenvolvedor escolher.
LLM ou SLM?
Agora, uma pergunta válida seria: sempre devo utilizar modelos gigantes como ChatGPT ou Gemini? E, sendo prático: depende do que está sendo proposto. É algo muito generalista? Se sim, modelos que tenham uma interpretação geral são uma boa pedida. Agora, se for algo específico de interpretação, a figura muda por alguns motivos. LLMs são treinados em uma quantidade de dados absurda e, como expliquei, isso dilui a probabilidade da resposta que queremos. Um SLM (Small Language Model) treinado para nossa tarefa específica, além de ser mais barata a chamada de API (ou até rodar localmente), pode performar melhor por alucinar menos por ter menos informação armazenada.
Imagine que cada peso do modelo é um fragmento de conhecimento armazenado (para simplificação do escopo desse post), então se temos fatos não correlacionados à tarefa no modelo e ele pode acessar por acidente, isso o faz menos performático. Geralmente, agentes têm como objetivo serem direcionados, então aumentar a distribuição de probabilidade para nosso objetivo soa muito melhor.
Definição do que é uma ferramenta
Bom, agora que foi dada a ideia do cérebro de um agente, vamos ao músculo. As ferramentas são o que realizam as tarefas. Dei exemplos simples de soma, multiplicação, chamar ambulância etc… Mas elas são funções desenvolvidas. O agente tem o papel de interpretar quando chamá-las e quais parâmetros preencher.
Imagine que você tem um atendente de uma lanchonete no WhatsApp que é um agente. Ele pode ter as ferramentas de criar pedido, verificar pagamento e notificar o cliente de que o pedido está sendo preparado ou saiu para entrega. O cliente, a princípio, irá escolher o pedido e dar as informações. Então o agente, com essas informações, invoca a ferramenta com os parâmetros preenchidos, criando o pedido. Em seguida, ele pode verificar o pagamento com a ferramenta de verificação e, quando for verificado que houve o pagamento, ele aciona a notificação. Veja que não disse mais de um prompt do usuário. O agente, se interpretar adequadamente, pode sequenciar as chamadas das ferramentas com base no prompt. Agentes dependem de diversos fatores: tokenização, treinamento (pré e pós), prompt base, prompt do usuário, definição de ferramentas, memória (cubro esse tópico depois), etc…
E como criamos uma ferramenta?
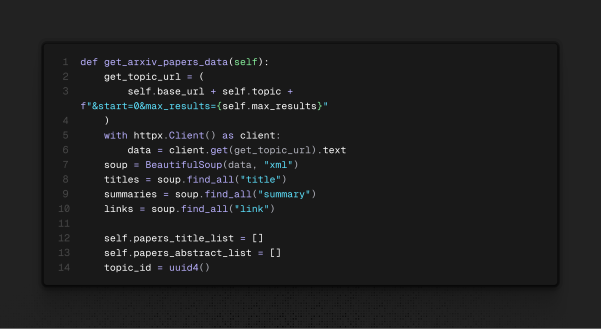
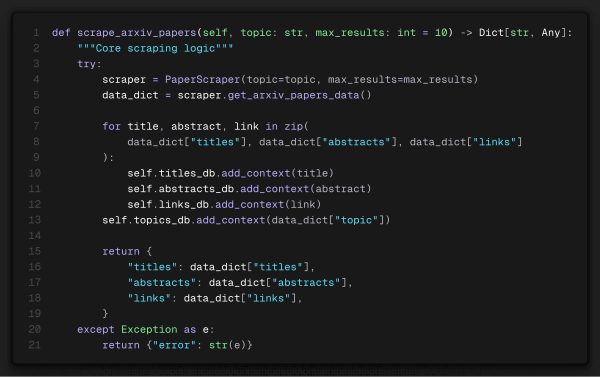
Ferramentas são passadas para o modelo como todo o resto: por texto. Definimos a ferramenta em código, documentamos essa ferramenta com comentário
@tool
def soma(x: int, y: int) -> int:
"""
Funcao destinada para soma de dois numeros inteiros, o resultado e a soma dos numeros que o usario pedir
ARGS:
x[int]: Numero inteiro que o usuario pediu
y[int]: Outro numero inteiro que o usuario pediu
RETURNS:
Retorna a soma dos numeros passados pelo usuario
"""
return x + y
A anatomia da função acima é dada da seguinte maneira: o decorador @tool adiciona o método para converter tudo em
string para o agente poder chamar e entender o que há dentro dela. A docstring é a documentação que o agente irá ler e
armazenar quando invocar a função e como ela se comporta. E, por fim, o retorno é o que o agente irá prover ao usuário.
Prompt de sistema: até que ponto devemos definir as regras
É importante deixar em mente que cada token afeta o próximo por as LLMs serem autoregressivas, ou seja, o primeiro prompt irá afetar todo o resto. Então, no desenvolvimento do nosso agente, é importante passar um prompt de sistema que irá colocar a regra de como o agente irá se portar com o usuário. Segue um exemplo do código que acompanhará este post e os próximos.
agent = Agent(
llm_model,
output_type = [EmpresasOutput, DbExists, DataPoints, Ticker],
system_prompt = (
r"""
You are a stock market expert agent, that whenever prompted to provide information about companies listed in the brazilian stock exchange (B3),
whenever the user provides the name of a company, you should provide the ticker associated with it. If the tool that seaches the ticker was already
used for this company before, you should check the previous messages sent for the ticker.
The tools provided should be used whenever the user asks for information about a company listed in B3, and you should always use them
TOOLS:
1. Check_tickers: Tool that checks if the tickers were already stored in the database, should be the first one to be called,
after that, if the tickers were not stored, call the store_tickers tool
ARGS: None
Returns: Returns a dictionary with a boolean whether the tickers were stored or not
2. store_tickers: Tool responsible for the task of getting the name and ticker from each company listed at ibovespa
it should be the first one called whenever the user asks for information about a company listed in B3
ARGS: None
Returns: Returns a dictionary where each company name is a key and the ticker is the value
3. get_ticker: Tool that fetches the ticker from the company name provided from the API
ARGS:
company_name[str]: Company name that the user asked about
Returns: Returns the ticker associated with the company name provided
4. get_ticker_plot: Tool that gets the ticker value daily and returns them from the dates given
ARGS:
company_name[str]: Company name that the user asked about
start_date[str]: Date that user asked about should be formatted as "YYYY-MM-DD", defaults to '2025-09-01'
end_date[str]: Date from end analisys should be formatted as "YYYY-MM-DD", defaults to '2025-10-01'
Returns: Returns a dictionary where each key is a date in the format YYYY-MM-DD and value the closing price of the stock on that date
Guidelines:
- Before the first tool call, you should always call the check_tickers tool
- If the tickers were not stored, you should call the store_tickers tool
- If the user asks for information about a company and you haven't the company's ticker in your memory, you should call the get_ticker tool
- If get_ticker tool doesnt return anything them, you should inform the user that the company was not found
- If the user asks to plot about a company, check if you have the ticker in your memory than call the get_ticker_plot tool with its ticker
- If the user asks for a plot of a company you should call the get_ticker_plot tool using the ticker stored in your memory
"""
),
deps_type = dict
)
Veja que nesse prompt base defino bem o escopo, ferramentas utilizadas e regras que o agente deve seguir.
Um detalhe importante é que isso é mais uma arte do que ciência até o momento, apesar do avanço rápido, que é:
o quão detalhado e rígido temos de ser? Rígido demais, o modelo não vai performar bem; mais livre, o modelo não irá
seguir as regras corretamente. A Anthropic tem investigado isso bastante e fizeram um post sobre (muitos conceitos não
foram apresentados ainda para não sobrecarregar o post, mas serão abordados em breve):
Agora que foram apresentados de maneira superficial os conceitos que fundamentam esses modelos de linguagem, é importante verificar padrões de codificação de ferramentas e do próprio agente.
Engenharia de software
Esse é um tópico sensível para muitos cientistas de dados e engenheiros de machine learning, mas se não for bem feito, tem altas chances de dar errado todo o agente. Vou entrar nos tópicos importantes para saber se o seu agente está chamando as funções corretamente com os parâmetros desejados, o que ele interpretou, erro caso ocorra algo inesperado, proteção de informação e certificar se o item passado para as ferramentas está no objeto desejado.
Logging (básico)
Logging é exatamente isso que o nome se propõe: registrar. Se você mantém o registro da tarefa do seu agente e das suas ferramentas, você pode ajustar de maneira mais efetiva. Gosto bastante de fazer os meus loggers em duas abordagens: Facade e Singleton.
No padrão Facade, eu crio uma classe base e as classes restantes herdam o logger com métodos de logging. Cada linha gerada irá indicar qual classe chamou o logging.
Exemplo:
class MainLogger:
"""
Base logger class for consistent logging across the application. All classes
will inherit from this class to utilize the same logging configuration.
"""
def __init__(self, logger_name = __name__):
self.logger = logging.getLogger(logger_name)
self.logger.setLevel(logging.INFO)
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
stream_handler = logging.StreamHandler(sys.stdout)
stream_handler.setFormatter(formatter)
if not self.logger.handlers:
self.logger.addHandler(stream_handler)
def info(self, message: str):
self.logger.info(message)
def error(self, message: str):
self.logger.error(message)
Aqui defino que cada classe vai ter o atributo do logger e chamo super().__init__() em cada classe, garantindo a
rastreabilidade. Claro que customizo algumas coisas nas classes que herdam para ser mais evidente o que está rolando.
Outra maneira popular é conhecida como Singleton, em que inicializamos em cada módulo o logger.
Não irei entrar no mérito de quando usar esses dois padrões por ser algo mais extenso e interessante. Mas, uma regra
da mão direita seria:
se tenho diversas classes e quero uma interface simplificada, utilize o Facade; se quiser algo mais complexo,
Singleton.
Logging (avançado)
Temos ferramentas mais avançadas que conseguem rastrear TUDO que está rolando. Irei citar aqui a ferramenta Logfire. Ela permite verificar tudo que está acontecendo no agente, desde o consumo de tokens até a chamada de funções e o que o agente está “pensando” para cada prompt.
Nomear variáveis e documentação de ferramentas
Dado que um modelo depende da documentação para performar bem, é necessário nomear as variáveis de parâmetro de forma clara para que o modelo saiba interpretar o prompt e extrair corretamente os dados para a ferramenta.
Etc…
Engenharia de software nessa área é fundamental para o sucesso do agente. Boas práticas devem ser padronizadas e seguidas em cada projeto não apenas para os programadores saber