Tabela de conteudos
- O que é um orquestrador?
- Mas por que usar um orquestrador?
- Exemplo de uma tarefa agendada
- Vamos à parte que interessa: o que estamos orquestrando?
- Como o Prefect funciona
- Work Pool
- Deployando o fluxo de fluxos
- Inicializando o work pool
- Estruturação do projeto
- Visualizar o resultado
- Considerações sobre o projeto
- Explicando cron
O que é um orquestrador?
Basicamente, ele coordena múltiplas aplicações, juntando as tarefas e definindo sua ordem de execução. No Python, temos alguns, como o Dagster, o Airflow e o utilizado aqui, que será o Prefect, que ganhou uma versão 3.0.
Mas por que usar um orquestrador?
Um orquestrador permite diversas coisas, entre elas, agendar a execução do código. Isso é muito útil para a área de dados. Imagine que você recebe dados diariamente e, com isso, precisa tratá-los toda vez. Além disso, os modelos podem ficar desatualizados por motivos de Data Drift, que é uma alteração da distribuição dos dados, fazendo com que nossos modelos fiquem descalibrados para a nova previsão. Com o orquestrador, podemos deixar o código agendado em alguma máquina para que execute os scripts e adicione os dados à nossa base de dados. Além disso, podemos ter uma regularidade sobre quando retreinarmos os modelos, com uma função que verifique se o modelo está perdendo precisão, acurácia, etc.
Exemplo de uma tarefa agendada
Para rodar o código acima, basta ter o Docker e o Docker Compose instalados e executar os seguintes comandos:
git clone https://github.com/mnsgrosa/prefect_mldump.git
cd prefect_mldump
docker compose up --build -d
Vamos à parte que interessa: o que estamos orquestrando?
Neste exemplo, estamos orquestrando o scraping de um subreddit (que pode ser alterado no script) e a adição ao banco de dados que, por motivos de simplicidade, fiz apenas com um CSV e uma API rápida no FastAPI, que será mostrada logo em seguida.
/prefect_mldump/main/orchestrator/api_tool.py
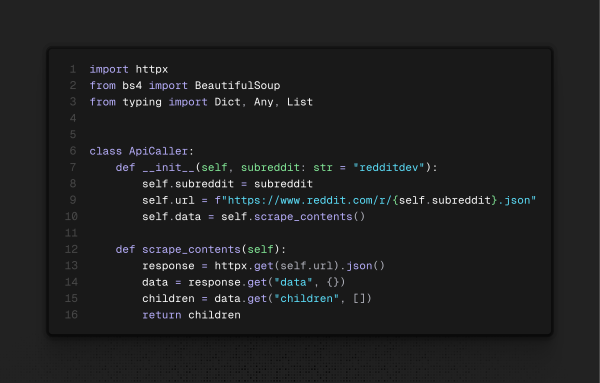
Ele utiliza a biblioteca httpx para fazer a requisição e recebe um JSON (ou um dicionário, para nós, usuários de Python). E basicamente é isso. Essa ferramenta é o retorno da classe responsável por extrair esse JSON, que será orquestrada para fazer o scraping a cada 2 horas.

Agora, a API é estruturada da seguinte maneira:
Imports que serão relevantes:
fastapi: Biblioteca responsável pela criação do que chamamos de endpoints, que são os responsáveis por realizar a operação no banco de dados. Um material que indico muito é o curso FastAPI do Dunossauro.typing: Tipagem dos objetos para que não haja inconsistência no FastAPI. O ideal seria utilizar o Pydantic, mas por motivos de velocidade, não o utilizei.uvicorn: Lib responsável por fazer a API rodar.

E agora, a criação dos endpoints:
-
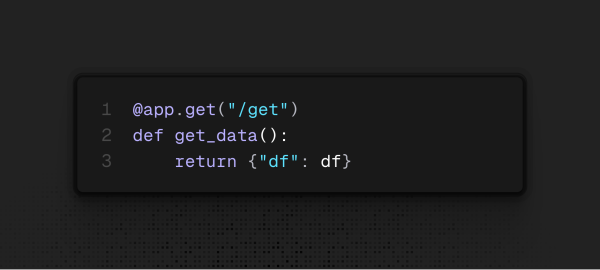
Get Método que deve retornar objetos da base de dados. Neste caso, ele não recebe nada e retorna a base de dados inteira, mas poderia simplesmente retornar um registro do banco de dados ou algo específico que o usuário desejar.
-
Post Método para adicionar informações à base de dados. Neste caso, existe um mini tratamento que fiz, mas poderia ser ainda mais simples, transformando os dados em uma lista de listas, sendo menos verboso.

Agora que foi explicada essa parte de API, podemos ir à parte da orquestração.
Como o Prefect funciona
Este orquestrador funciona com o que chamam de flows (fluxos). Cada fluxo tem tasks (tarefas). Essas tarefas são os “átomos” do que fazer, e os fluxos têm um limite do que pode ser realizado. Assim, o ideal é deixar o código o mais modularizável possível, por motivos de reutilização e para manter a organização proposta pelo Prefect. Outra maneira de ajustar isso seria a criação de um fluxo de fluxos, onde um fluxo principal pode receber múltiplos subfluxos para minimizar o impacto em cada um. Dito isso, o conceito que vou demonstrar envolve as tarefas e os flows que serão orquestrados para agendamento. Abaixo, um exemplo seguindo os padrões sugeridos pela própria Prefect:
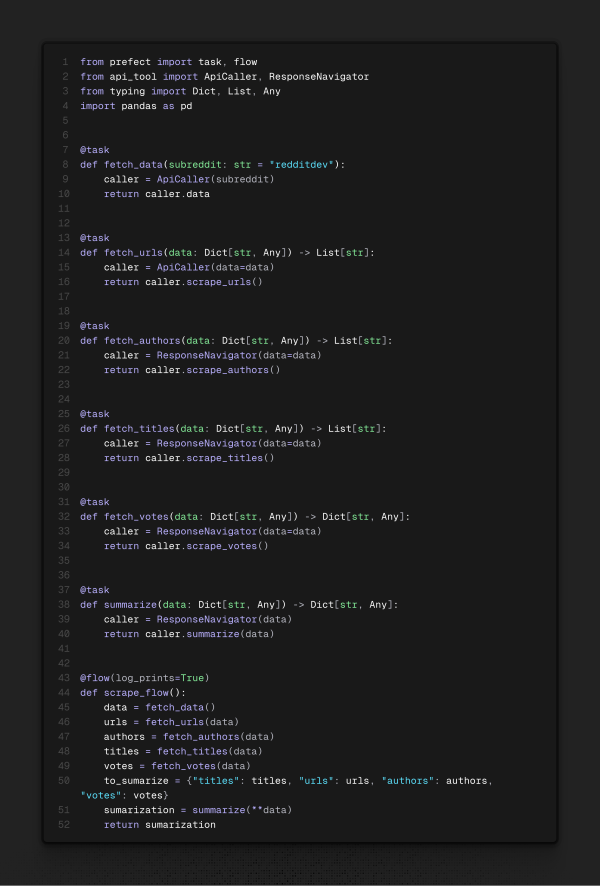
E agora, um exemplo menos indicado:
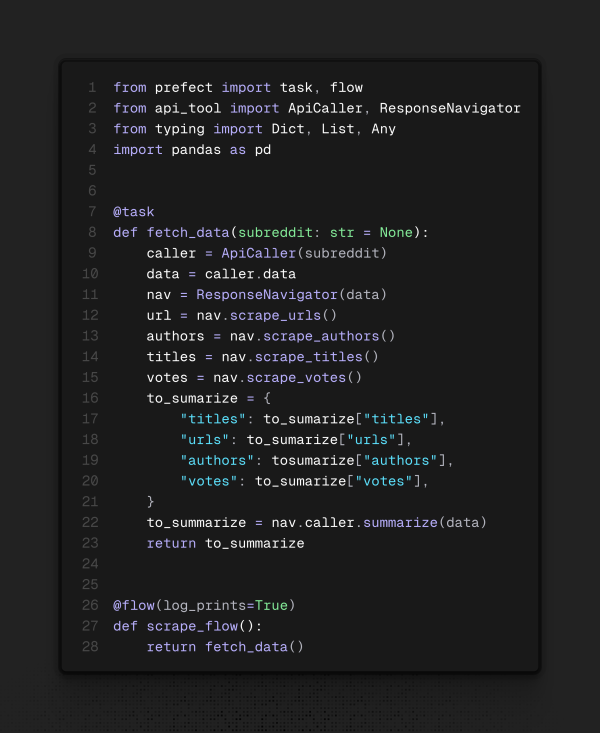
Repare nos decoradores (@task, @flow) acima das funções. Eles dão métodos adicionais à função que nos serão úteis para o deploy (implantação) do agendamento dos flows. Por fim, temos o último flow a ser criado: o de postar os dados obtidos da internet em nossa base de dados.
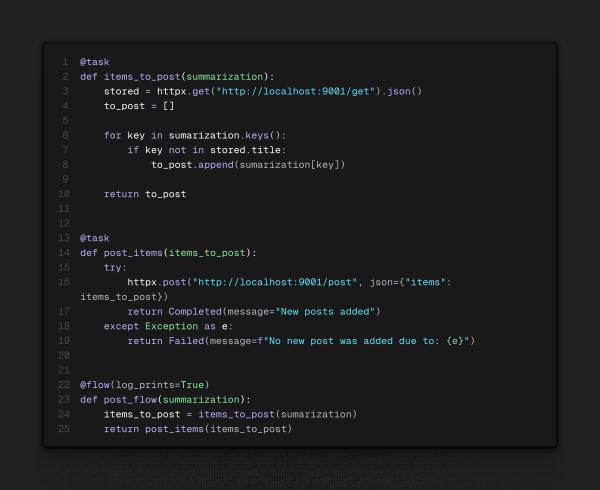
Repare que agora a tarefa final retorna um objeto diferente: ele se chama State (estado) e ajuda a gerenciar o seguimento dos fluxos. Caso em algum momento um dos fluxos falhe, podemos alterar o que o orquestrador executará. Seguindo as boas práticas sugeridas, faremos então um fluxo de fluxos, já que um depende da saída do outro, ficando da seguinte maneira o fluxo final:
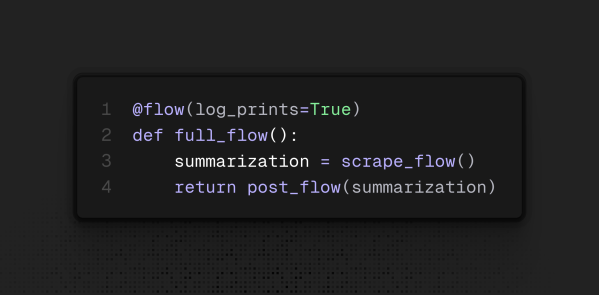
Antes de executarmos o deploy desse flow, precisamos criar o que chamam de work pool.
Work Pool
É o responsável por ligar a camada de orquestração à camada de infraestrutura, fazendo assim os flows serem executados na infra desejada. Neste caso, será na minha máquina, mas poderia ser implementado na AWS, GCP ou outra nuvem disponível. Link da documentação completa.
Dito isso, como criamos o work pool? Pode ser feito de duas maneiras principais: executando o seguinte comando:
prefect work-pool create [opcao] [nome_do_work_pool]
E a maneira que fiz para o teste com o Docker Compose, com um script Python:
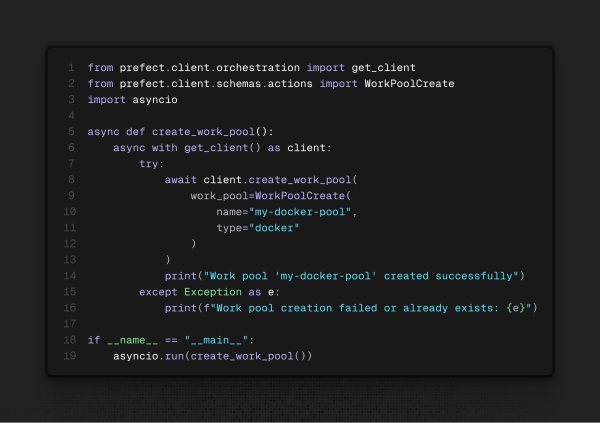
Aqui, para criá-lo no CLI, utilizaríamos o seguinte comando:
prefect work-pool create --type=docker my-docker-pool
A flag --type=docker é necessária, pois o serviço que será utilizado é o Docker. Com o work pool criado, podemos “deployar” o agendamento e, após isso, acionamos o work pool.
Deployando o fluxo de fluxos
Agora, os métodos adicionais serão utilizados:

A função full_flow recebeu o método from_source(), que permite construir o flow a partir do arquivo .py original. Por fim, temos o .deploy(), que gera as principais informações para o deploy, sendo elas: nome do deploy, nome do work pool e o agendador (com sintaxe cron, que irei explicar no final deste post, mas, neste caso, ele passa a seguinte informação: “a cada 2 horas, no minuto 0”).
Basta executar o script para criar o deploy no work pool fornecido. Agora, falta inicializar o work pool para agendar a execução do código.
Inicializando o work pool
Para que o work pool seja inicializado, basta executar o seguinte código no CLI:
prefect worker start -p [nome_da_pool] [opcoes]
No nosso caso, se traduz para:
prefect worker start -p "my-docker-pool" --type "docker"
Essa última opção (--type "docker") se deve ao fato de estarmos executando em um contêiner Docker. Caso estivesse rodando fora, na sua máquina, não precisaria dessa opção final. E pronto! O processo está agendado para executar periodicamente de acordo com o cron. Mas, no caso do projeto, o Docker Compose já faz tudo por você, então aqui vai como foi feito:
Estruturação do projeto
Fiz o projeto com o Docker Compose para que fosse mais fácil rodar os serviços de backend e do Prefect sem ter de abrir múltiplos terminais. Criei uma imagem customizada simples, sem muitas técnicas para deixá-la mais leve (como o uso de distroless), e nos serviços restantes utilizei a imagem oficial do Prefect com Python 3.12.
Minha imagem customizada ficou da seguinte maneira:
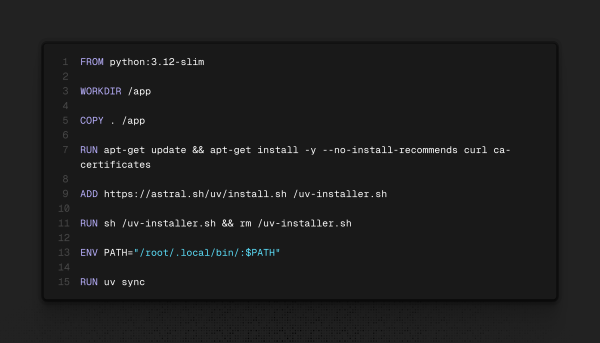
E a invoco em dois serviços: o responsável pelo backend e o responsável por criar o work pool.
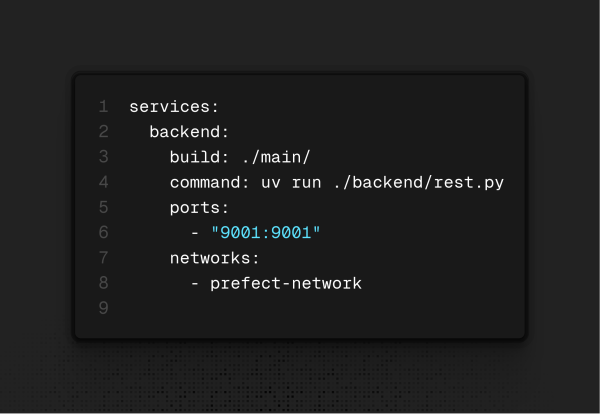
Primeiro serviço: Backend
Ele roda a imagem customizada que criei para executar o backend com uv.
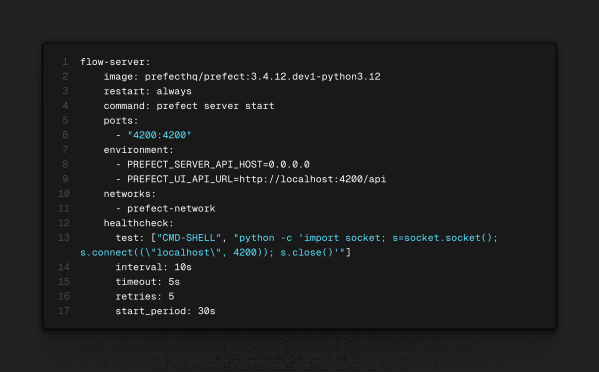
Segundo serviço: Flow Server
Roda a imagem oficial do Prefect 3.12 e executa o comando para inicializar o servidor, onde teremos o dashboard para acompanharmos o andamento dos flows.
Terceiro serviço: Work Pool Creator
Também rodando a imagem que criei para criar o worker, mesmo sabendo que poderia ser executado via CLI com a imagem do Docker.
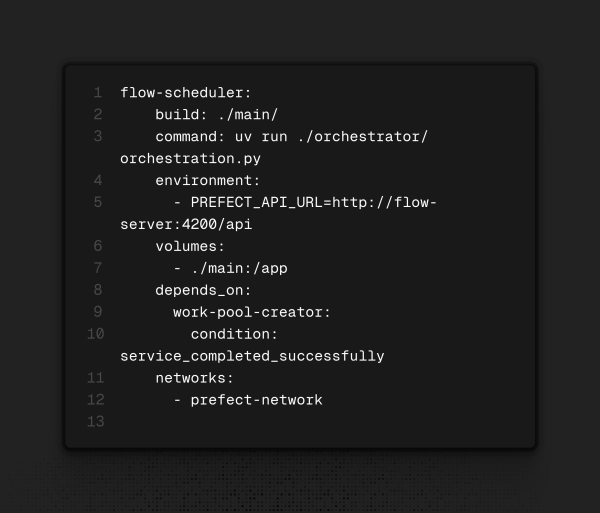
Quarto serviço: Flow Scheduler
Utilizando a imagem customizada, roda os scripts para “deployar” os serviços após a criação do work pool especificado no script.
E, por fim, o último serviço: Flow Start
Está utilizando a imagem customizada, pois a imagem base do Prefect não vem com o módulo do Docker, o que acaba tornando necessário o uso de:
uv add "prefect[docker]"
para adicioná-lo ao pyproject.toml.

Visualizar o resultado
Agora, basta acessar os seguintes links para ver o resultado: o backend aqui e o dashboard do orquestramento aqui.
Considerações sobre o projeto
Há muita margem para melhoria nesse projeto. A intenção era simplesmente mostrar o básico. É possível deixar os flows assíncronos, limitar a concorrência de processamento, etc. O meu projeto inicial utilizaria tudo isso, mas a API da qual eu estava pegando os dados climáticos foi desativada (ate o momento), o que me impediu de seguir com o projeto, apesar de ele já ter uma estrutura mais avançada.
Explicando Cron
Cron e um agendador de tarefas em sistemas operacionais unix e ele segue a seguinte semantica (minuto, hora, dia, mes, dia da semana) ou seja (* * * * *) siginifica todo minuto o asterisco representa sempre e */n acada n unidades sendo assim meu cron 0 */2 * * * representa: a cada duas horas

Deixe um comentário