
A ideia inicial
Minha ideia inicial foi criar um agente com ferramentas para pegar títulos, introduções e GitHub do Papers with Code, que agora virou Trending Papers. Enquanto estava programando a transição para o ArXiv, lançaram o Trending Papers, então é uma possibilidade fazer para ele também. A ideia teve um ponto de partida que foi a criação de um grupo de papers da minha faculdade — achei que seria interessante me propor o desafio de criar um agente conversacional com ferramentas de scraping e base vetorial para busca pelo nome do tópico. O plano é aprimorar a ferramenta futuramente para acessar ferramentas internas, como deadlines de conferências ou eventos da faculdade.
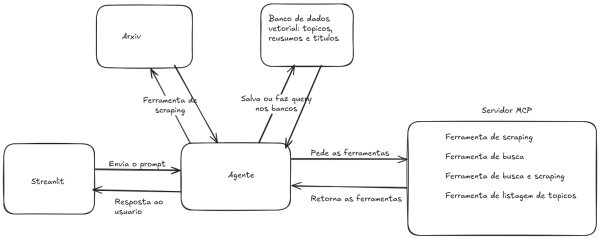
Fluxo do agente
O fluxo funciona da seguinte maneira: o agente se conecta ao servidor MCP, que está ligado na porta 8000, e solicita as ferramentas ao servidor. Em seguida, ele passa a interpretar os prompts do usuário e, caso uma ferramenta seja solicitada, ele a executa e retorna uma resposta estruturada ao usuário.
Como iniciar o agente
Primeiro pegue a key da API Groq nesse link GROQ
Basta clonar o repositorio
git clone https://github.com/mnsgrosa/llm_arxiv.git
Instalar a ferramenta docker e docker compose e em seguida entrar no diretorio e jogar o seguinte comando no terminal
crie um .env contendo a seguinte linha
GROQ_API_KEY = sua_key_aqui
e rodar o comando abaixo
docker compose up -d
O dashboard fica localizado aqui Dashboard
Link para o git do projeto
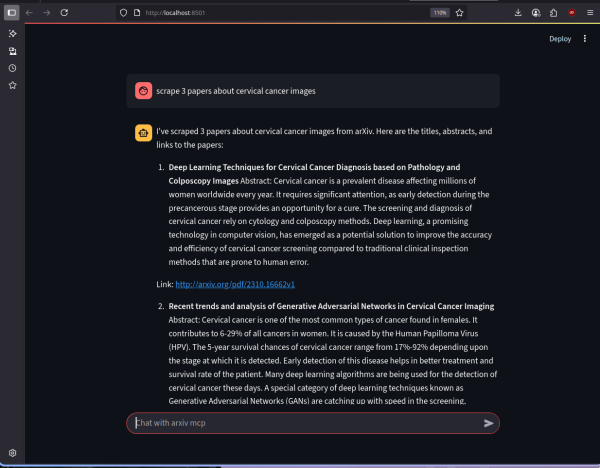
Ferramentas utilizadas
FastMCP, Httpx, BeautifulSoup4, Chromadb, Gradio, Langchain, LangGraph, Langchain_groq
Leitura do site
Para as requisições do ArXiv, utilizei o Httpx — uma ferramenta mais recente que a clássica requests do Python. Escolhi essa ferramenta por ter mais familiaridade, por indicação de colegas, e por sentir que é mais rápida. Para leitura da resposta do site, utilizei o BeautifulSoup4.
Criação do agente
Para criar o MCP, utilizei a biblioteca FastMCP e, para o agente em si, usei o Langchain e o Langchain_groq para ligar à API gratuita do modelo Llama3-8b-8192.
Ideias por trás do código e o código
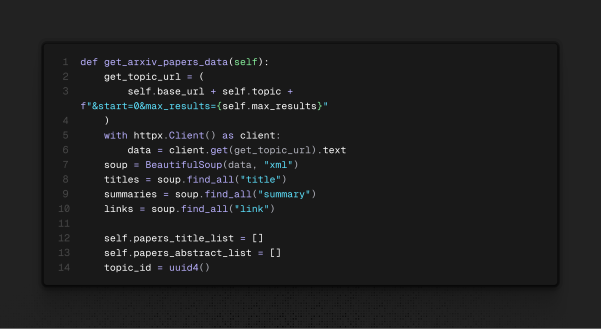
- Como foi feito o scraping:
O ArXiv tem uma página destinada a requisições por tópicos. Dito isso, é de fácil acesso com o Httpx, e as tags HTML também facilitam o processo por serem'title','summary'e'link', bastando chamar o métodofind_all()da biblioteca BeautifulSoup4. Então é uma questão de lógica de programação simples para salvar os itens.
- Criação das ferramentas do agente:
Criei um arquivo chamadoshared_paper_tools.py. Nesse arquivo, há uma classe que controla o que o agente irá fazer. Ao ser inicializada, ela cria 3 bases de dados utilizando o Chromadb. A principal, que é a de tópicos, é fundamental para localizar os itens nas outras bases, que são as que salvam os títulos e introduções de cada paper.
-
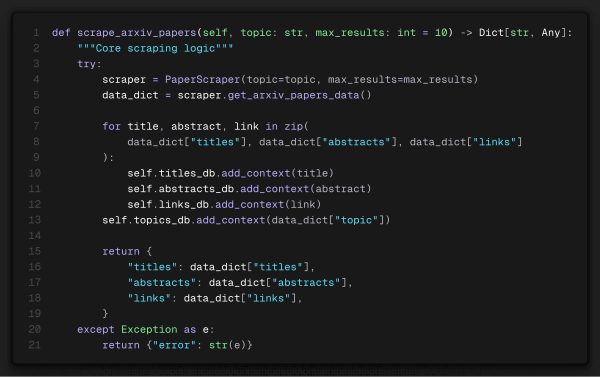
scrape_arxiv_papers:
Temos um método simples que usa o scraper e salva os itens na base de dados.
-
search_stored_papers:
Esse método faz a LLM interpretar qual o tópico desejado pelo usuário e depois verifica se há algum tópico parecido no banco de dados.

-
get_or_scrape_papers:
É um método mais versátil: se não encontrar na base de dados, ele irá chamar os dois métodos acima; se existir, só o método de pegar o paper.

-
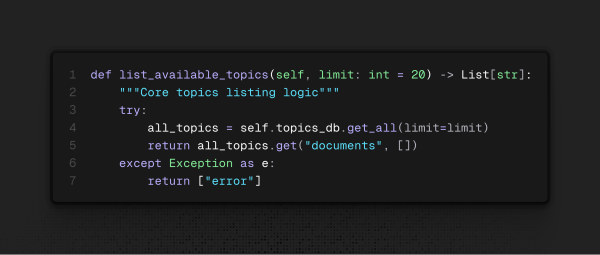
list_available_topics:
Verifica quais tópicos estão na base de dados vetorial.
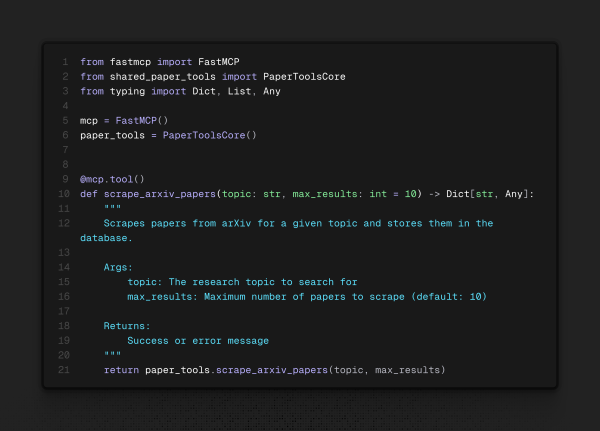
- MCP server:
Aqui há um ponto crucial: cada código deve ter uma docstring bem feita para o agente. Ele vai se orientar pela docstring sobre o que fazer. Na docstring, deve-se explicar os parâmetros da função e uma descrição do que ela faz para, quando for pedida uma tarefa, o agente entender que é aquela ferramenta específica que você deseja. De resto, basta importar o objeto criado das ferramentas e chamá-los em cada função. Segue um exemplo de função feita — perceba o annotator acima dela.
-
Agente:
Algumas partes importantes serão citadas aqui, mas muitas partes serão puladas por ser um script muito grande. Primeiramente, os imports:

Aqui, gostaria de falar sobre alguns imports importantes para criar o MCP, sendo eles oAgentExecutorecreate_tool_calling_agentda linha 7 eload_mcp_toolsecreate_react_agentdas linhas 13 e 14. Essas são as classes responsáveis por transformar a LLM em um agente. Como mostrado nos métodos abaixo:
Aqui temos a inicialização do
client sse, que é o método de conexão com o servidor MCP. Outra parte importante é o prompt base do agente: ele é quem vai guiar a LLM para tomar decisões. Em seguida, temos a criação do agente comcreate_tool_calling_agent, dando wrapping emAgentExecutor, que permite a execução das ferramentas. E, por fim, a função que permite a conversação com o agente, salvando as mensagens na memória.
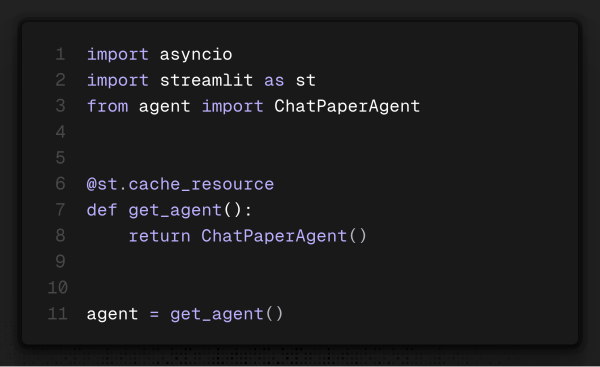
Por fim, não é necessário fazer um loop devido ao fato que o streamlit naturalmente esta loopando e com isso zerando o que nao for posto no cache do codigo com as seguintes linhas:
Próximos passos
Os próximos passos são criar algumas ferramentas adicionais que seriam úteis para minha faculdade (CIN/UFPE).

Deixe um comentário